Prometheus 와 Grafana 란?
- Prometheus : 오픈 소스 기반의 모니터링 시스템으로 Alerting을 지원.
- Grafana : 오픈소스 매트릭 데이터 시각화 도구로 메트릭(Metric) 분석 플랫폼
보통, Prometheus 와 Grafana 가 같이 언급되는데
Prometheus 가 대상 시스템(Target System) 들에서 필요한 모니터링 지표를 수집하여 저장하고
Grafana 에서 이를 시각화(Visualization)한다.
Prometheus

오픈 소스 기반의 모니터링 시스템으로 각종 모니터링 지표를 수집하여 저장하고 검색할 수 있는 시스템이다.
현재 Kubernetes 상에서 가장 많이 사용하는 오픈 소스 기반 모니터링 시스템이며,
간단한 텍스트 형식으로 메트릭(Metric)을 쉽게 노출 가능하며, 데이터 모델은 Key-Value 형태로 레이블을 집계한다.
또한, 이해하기 쉬운 PromQL 쿼리 언어를 사용하여 간단하게 경고와 Ruleset 을 정의 가능하다.
대부분의 모니터링 도구가 Push 방식 즉, 각 서버에 클라이언트를 설치하고 이 클라이언트가 메트릭(Metric) 데이터를 수집해서 서버로 보내면 서버가 모니터링 상태를 보여주는 방식을 취한다.
하지만 Prometheus는 Pull 방식을 사용하여, 서버에 클라이언트가 떠 있으면 서버가 주기적으로 클라이언트에 접속해서 데이터를 가져오는 방식을 취한다.
※ Metric
Prometheus 는 근본적으로 모든 데이터를 시계열로 저장하고, 모든 시계열 데이터는 고유한 메트릭(Metric)명과 Optional 하게 들어갈 수 있는 Key-value 쌍의 라벨로 구분된다.
매트릭명 {라벨명=값, 라벨명=값} 샘플링 데이터
간단히 나타내면 Prometheus의 메트릭(Metric)은 위처럼 구성되어 있으며, 예시를 보자면 아래와 같다.

node_cpu_seconds_total 이라는 메트릭명에, cpu와 mode 라는 라벨이 붙어있다.
cpu와 mode 라벨에 각각 0, idle 이라는 값을 가진 메트릭 값은 48649.88 이라는 의미이다.
이 데이터가 Prometheus 에 수집될 때 timestamp 값이 같이 들어가게 되고, 이렇게 쌓인 메트릭 데이터들을 시계열 데이터 라고 한다.
참고) Prometheus의 Metric type
Prometheus에는 크게 아래의 4가지 메트릭(Metric) 타입이 존재한다.
- counter: 증가하거나 0으로만 리셋 가능. (ex. total request count)
- gauge: 증감 혹은 특정 값으로 설정 가능. (ex. number of running processes)
- histogram: 특정 범위(bucket) 내에서 값의 빈도수를 표현. (ex. request duration)
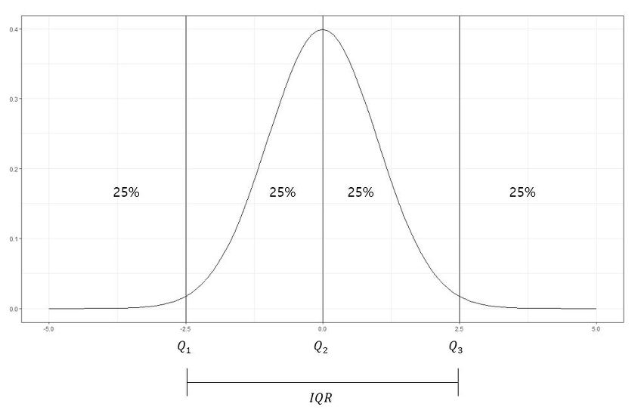
- summary: histogram 과 유사, 사분위수를 나타냄. (ex. request duration)
- 1/4(25%)씩 네조각으로 나누는 지점의 숫자를 가리키는 용어
※ Push 방식과 Pull 방식
- Push : 데이터를 가진 곳에서, 필요한 곳으로 보내준다.
- Pull : 데이터가 필요한 곳에서, 가진 곳에 접속하여 데이터를 긁어간다.
Push 방식은 중앙집중형이기에, 중앙 모니터링 시스템이 데이터 수집 항목, 수집할 서버를 모두 관리한다.
반면, Pull 방식은 분산형으로, 중앙시스템은 에이전트가 보내주는 데이터를 긁어갈 수만 있으면 어떤 데이터를 수집할 지 중앙에서 변경할 수 있다.
보안 측면에서는 Push가 Pull보다 유리하다
Pull방식은 수집 대상 서버에서 중앙 폴러가 접근할 수 있는 포트, IP 등을 수신 대기해야 한다.
HA 측면에서 Pull이 Push 방식보다 유리하다.
Data-Backend에서 장애가 발생하더라도, Pull 방식에선 수집 Host에 영향이 없으나 Push 방식에선 데이터 전송 재시도 등 Host에 영향이 생긴다.
참고) 데이터 수집
데이터 수집 요청은 정기적으로 발생한다. 일반적으로 각 대상에 10~60 초마다 요청을 보내도록 구성할 수 있다.
즉, 실시간이 아닌 어디까지나 근사값이라는 점을 인지해두어야 한다.
예를 들어, 15초 단위로 설정했다고 가정할 때 15초 내에 CPU가 올라갔다 내려와서 수집(Pull) 하는 순간에는 CPU가 내려간 값만 관측될 수 있다.
Prometheus Architecture 구성
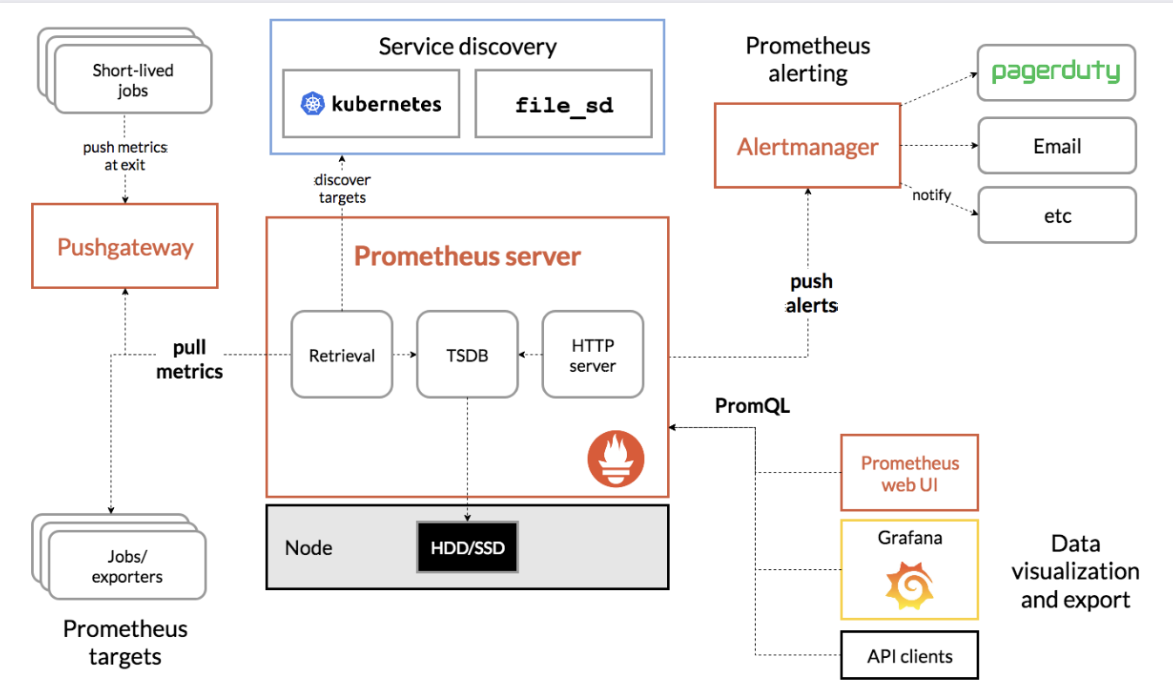
- Service discovery: Prometheus 는 기본적으로 모니터링 대상 목록을 유지하고 있으며, 대상에 대한 ip 나 기타 접속 정보를 설정 파일(prometheus.yml)에 주어서 모니터링 정보를 가져오는 방식을 사용한다.
- Push gateway: Pushgateway는 Proxy Forwarding 을 해서 접근할 수 없는 곳에 데이터가 존재하는 경우에 사용할 수 있는 대안이다.
- Application 이 Pushgateway 에 메트릭(Metric)을 push 한 후, Prometheus Server 가 Pushgateway에 접근해 metric을 pull 해오는 방식으로 동작.
- excporter & job: Prometheus 에게 데이터를 수집할 수 있도록 메트릭(Metric)을 노출하는 Agent.
- exproter 는 서버 상태를 나타내는 Node exporter, SQL exporter 등 다양한 커스텀 Exporter 가 개발되어 사용되고 있으며,
- 이 exporter를 사용하여 Metric을 수집하고 HTTP 통신을 통해 매트릭(Metric) 데이터를 가져갈 수 있도록 /metrics 라는 HTTP 엔드포인트를 제공한다.
- 그러면, Prometheus 서버가 이 exporter 의 엔드포인트로 HTTP GET 요청을 날려 매트릭(Metric) 정보를 수집(Pull) 한다.
- Alert Manager: 메트릭(Metric) 에 대한 어떠한 지표를 걸어놓고 그 규칙을 위반하는 사항에 대한 알람을 전송하는 역할을 한다.
- Data Visualization: Prometheus 가 자체적으로 제공하는 web UI 에서 테이블 및 그래프 형태로 볼 수 있다. 하지만, 시각화 도구가 부족하여 이를 직접 사용하기보다는 대게 Grafana 라는 데이터 시각화 툴(Data Visualization Tool) 을 이용하여 시각화 하고 있다.
- TSDB: 수집된 정보는 별도의 데이터베이스 등을 사용하지 않고, 그냥 로컬 디스크에 저장한다. 설치가 매우 쉽다는 장점이 있으나 스케일링이 불가능하다는 단점으로 증설이 필요할 경우 디스크를 증설한다.
- Prometheus 가 수집해서 TSDB 에 저장되어 있는 데이터는 PromQL 을 통한 쿼리를 통해 조회가 가능하다.
- Retrieval : Service discovery 로부터 모니터링 대상 목록을 받아오고, exporter로 대상으로부터 메트릭을 수집하는 모듈이 Prometheus 내의 Retrieval 이라는 컴포넌트이다.
Grafana

그라파나는 오픈소스 매트릭 데이터 시각화 도구로 메트릭 분석 플랫폼을 지향하고 있다. 2014년에 처음 릴리스되었으며, 매트릭 정보를 시각화하고 대시보드를 구성하기 유용하다. Prometheus는 물론 AWS CloudWatch, Azure Monitor 와 같은 데이터 소스를 비롯해 InfluxDB, ElasticSearch 등을 기반으로 로그 데이터를 지원하는 등 더 많은 데이터 소스를 지원하고 있다.
서버 리소스의 매트릭 정보나 로그 같은 데이터를 가져와 시각화하는데 사용하며, 시각화한 그래프에서 특정 리소스가 임계값 이상으로 사용되었을 때 알림을 전달 받을 수 있는 기능도 제공한다. 오픈소스 툴킷인 만큼 커뮤니티가 많이 활성화되어 직접 대시보드를 작성할 수도 있지만, 사용자들이 만들어놓은 대시보드를 Import 하여 손쉽게 구성 가능하다.
현재 그라파나 랩(Grafana Labs)에서 개발하고 있으며, 이 회사에서 Grafana Enterprise와 Grafana Cloud 와 같은 상용 서비스도 개발하고 있다.
현재 그라파나는 페이팔(Paypal), 이베이(ebay), 인텔(Intel), Dell Technologies, SIEMENS, Unity, Nutanix 등 다양한 세계적인 기업들에서 활용되고 있다.
Reference
'AWS(Amazon Web Service) > Prom+Grafana+cAdvisor' 카테고리의 다른 글
| [Prometheus/Shell script] node exporter 와 mysqld exporter 설치 (0) | 2022.06.23 |
|---|---|
| [AWS] Prometheus+Grafana+cAdvisor 설치 (0) | 2021.11.19 |
| [AWS] Prometheus+Grafana 설치 (2) (0) | 2021.11.17 |
| [AWS] Prometheus+Grafana 설치 (1) (0) | 2021.11.16 |


