[이론]
(1) Kubeadm : 쿠버네티스에서 공식 제공하는 클러스터 생성/관리 도구. 여러 대 서버를 쿠버네티스 클러스터로 손쉽게 구성할 수 있다.
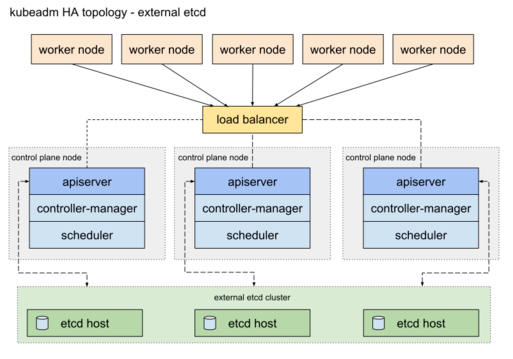
- 여러 대의 마스터 노드를 구성하고 그 앞에 로드밸런서.
- 워커 노드들이 마스터 노드에 접근할 때는 로드밸런서를 거쳐 접근
- 쿠버네티스 클러스터의 데이터 저장소 역할을 하는 etcd 클러스터를 마스터 노드에 함께 설치해서 운용하는 방법.
- 스택 etcd 라고 한다.
- 필요에 따라 etcd 클러스터를 마스터 노드가 아닌 다른 곳에 구성해두고 사용할 수 있다.
(2) Kubespray : 상용 서비스에 적합한 보안성과 고가용성이 있는 쿠버네티스 클러스터를 배포하는 오픈 소스 프로젝트.
- Kubespray는 서버 환경 설정 자동화 도구인 앤서블(ansible)기반으로 개발.
- 온프레미스 환경에서 상용 서비스의 쿠버네티스 클러스터를 구성할 때 유용함.
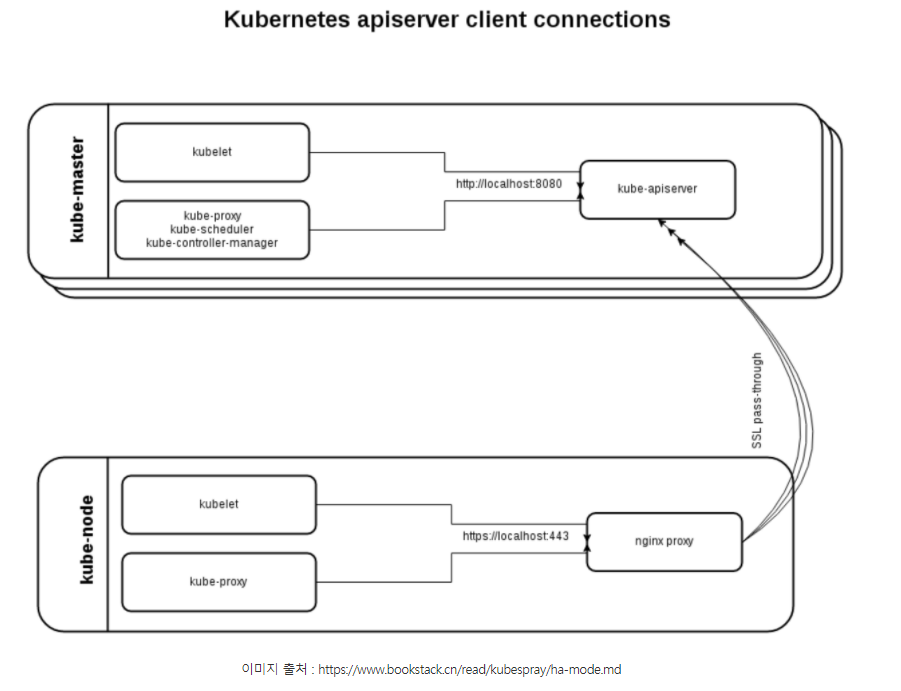
- Kubeadm처럼 별도의 로드밸런서를 사용하지 않고 노드 각각의 nginx가 리버스 프록시로 실행된다.
- 이 nginx-proxy가 전체 마스터 노드를 바라보는 구조.
- 그래서 쿠버네티스의 컴포넌트들은 직접 마스터 노드와 통신하지 않고 자신의 서버 안 nginx와 통신한다.
- 마스터 노드의 장애 감지는 Health-Check 를 이용해 nginx가 알아서 처리한다.
[실습]
쿠버네티스 클러스터 구성은 마스터 노드(서버) 3대, 워커 노드(서버) 2대로 진행.
● 마스터 노드(Master Node)
- 노드들의 상태를 관리하고 제어.
- 쿠버네티스의 데이터 저장소로 사용하는 etcd를 함께 설치하거나 별도 노드에 분리해서 설치하기도 한다.
- 마스터 노드 1대만 설치할 수도 있지만 상용 서비스라면 보통 고가용성을 고려해 3대~5대 설치.
- Kube-controller-manager가 활성화(Active) 상태로 동작할 수 있는 리더 마스터 노드는 1대이다.
● 워커 노드(Worker Node)
- Kubelet 이라는 프로세스(에이전트)가 동작.
- 마스터 노드의 명령을 받아 사용자가 선언한 파드나 잡(Job)을 실제 실행.

(1) GCP(구글 클라우드 플랫폼) 접속.

- [Compute Engine] 탭에서 [인스턴스 만들기]
(2) VM 인스턴스 5개 생성
- [리전] : asia-northeast3(서울)
- [영역] : asia-northeast3-a
- [시리즈] : E2
- [머신 유형] : e2-standard-4(vCPU 4개, 16GB 메모리)
- [부팅 디스크] : OS는 Ubuntu 16.04 LTS
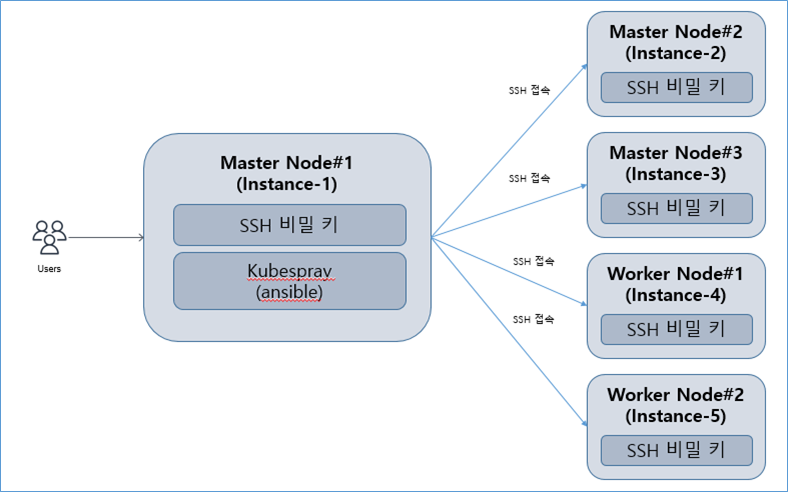
(3) Kubespray로 쿠버네티스 클러스터 구성을 진행
- 마스터 노드 #1인 Instance-1 서버에서 다른 서버에 원격 접속(SSH)이 가능하도록 설정
- Kubespray 설치
- 클러스터로 구성할 서버 정보를 설정
- 클러스터 설치 옵션 확인
- Kubespray가 제공하는 앤서블 플레이북(ansible playbook)을 실행
(3-1) SSH 키 생성과 배포
: 앤서블을 이용한 원격 서버 접근은 SSH로 이루어지므로 모든 VM 인스턴스에 SSH 키를 전송할 필요가 있다.
(3-1-1) 마스터 노드#1 (Instance-1)에 SSH 공개키와 비밀키 생성
sudo ssh-keygen -t rsa
: -t rsa 옵션은 RSA 방식의 암호화 키를 만들겠다는 뜻이다.
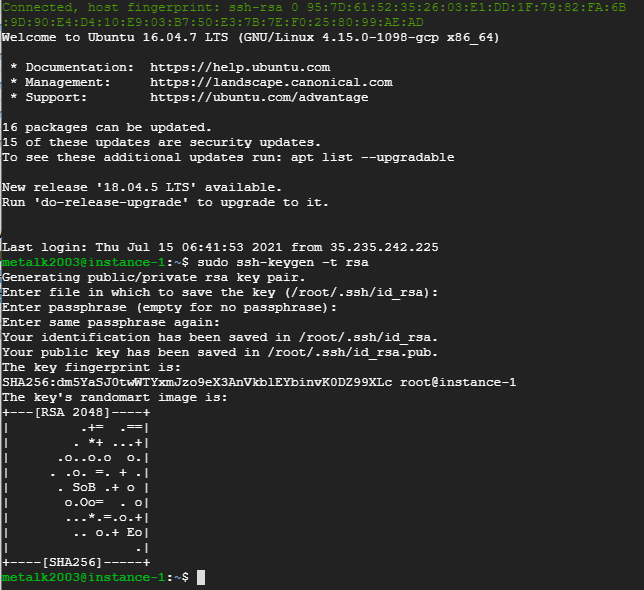
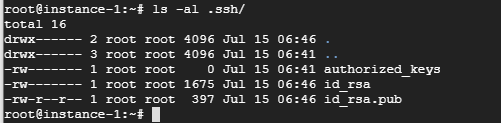
- 성공적으로 생성하였다면 .ssh 디렉터리 안에 비밀 키 id_rsa 파일과 공개 키 id_rsa.pub 파일이 생성됨.
- ls -al .ssh/ 명령으로 확인
(3-1-2) 프로젝트 안 모든 VM 인스턴스에 SSH 공개 키 배포.
: 구글 클라우드에서 제공하는 메타데이터 기능을 이용.
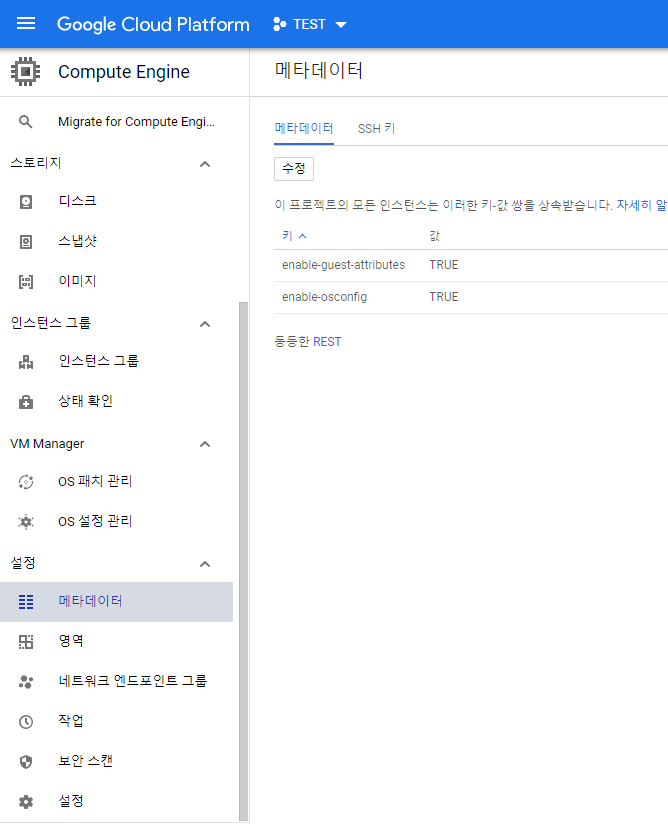

- [SSH 키] > [수정]

- [항목 추가]
- .ssh/id_rsa.pub 파일의 내용을 키 데이터에 복사
- [저장]

- 이제 생성한 모든 서버에 SSH 공개 키를 자동으로 배포하게 된다.

- 각 인스턴스의 .ssh/authorized_keys 파일을 보면 정상적으로 배포되어 있는 것을 확인할 수 있다.\
※ GCP의 VM 인스턴스가 아니라 자체 준비한 서버에서 이 과정을 진행하려면 다음 명령을 이용하여 준비한 5대의 서버에 SSH 공개 키를 배포
$ ssh-copy-id 계정이름@서버IP
$ ssh-copy-id root@10.178.0.17
$ ssh-copy-id root@10.178.0.18
$ ssh-copy-id root@10.178.0.19
$ ssh-copy-id root@10.178.0.20
$ ssh-copy-id root@10.178.0.21
※ 위의 명령어로 원격 접근하기 어려운 환경이라면 대상 서버들에 직접 접속하여 vi .ssh/authorized_keys 로 파일을 열어 공개 키를 복사.

$ ssh instance-2 hostname
(3-2) Kubespray 설치
- 마스터 노드 #1 역할인 instance-1에서 계속 진행.
- 먼저, sudo apt update 명령으로 우분투 패키지 매니저를 최신 상태로 업데이트.
$ sudo apt update
- Kubespray는 필요한 관련 패키지를 파이썬 패키지 매니저인 pip 로 설치한다. ubuntu 16.04 에는 기본적으로 설치가 되어 있지 않았으므로 sudo apt -y install python-pip 명령으로 설치
$ sudo apt-get -y install python3-pip
$ sudo apt-get update
$ curl "https://bootstrap.pypa.io/pip/3.5/get-pip.py" -o "get-pip.py"
$ python3 get-pip.py
- Kubespray를 깃허브(github)에서 클론.
$ git clone https://github.com/kubernetes-sigs/kubespray.git

- cd kubespray/ 명령으로 kubespray 디렉터리로 이동한 후 git checkout -b v2.11.0 명령을 실행
$ cd kubespray/
- 여기에서 설치할 2.11.0으로 체크아웃
$ sudo git checkout -b v2.11.0
- git status 명령의 실행 결과가 On branch v2.11.0 이라고 나온다면 성공적으로 해당 버전이 지정된 것.

- 클론한 파일들을 확인
$ ls -al

- 파일들 중 requirements.txt 에는 pip로 설치할 패키지 정보가 있다. Kubespray가 필요로 하는 관련 파이썬 패키지이다.
$ cat requirements.txt

- requirements.txt 를 이용하여 Kubespray 에서 필요한 패키지를 설치한다. (root 권한으로 진행)
$ sudo pip3 install -r requirements.txt
$ ansible --version

(3-3) Kubespray 설정
: 마스터 노드 #1(instance-1)을 포함해 클러스터로 구성할 모든 서버의 정보와 설치 옵션을 설정할 차례.
- 클러스터 이름(새로 만들 디렉토리 이름)을 mycluster 로 한다.
- inventory/sample 디렉토리에는 설정에 필요한 기본 템플릿이 있다.
- 기본 템플릿을 별도 디렉토리로 복사해서 mycluster 클러스터 설정에 사용하도록 한다.
$ cp -rfp inventory/sample inventory/mycluster
- 복사가 정상적으로 되었는 지 확인. group_vars 와 inventory.ini
$ ls inventory/mycluster

● group_vars 디렉터리 안에는 클러스터 설치에 필요한 설정 내용이 있다.
● inventory.ini 파일에는 설치 대상 서버들의 정보를 설정한다.
(3-3-1) group_vars
- 여기에는 group_vars 디렉토리에 별도의 클러스터 설치 옵션들을 설정하지 않고 바로 쿠버네티스 클러스터를 구성하므로 group_vars 디렉토리는 어떤 역할을 하는 지 살펴보기만 한다.
$ tree inventory/mycluster/group_vars/
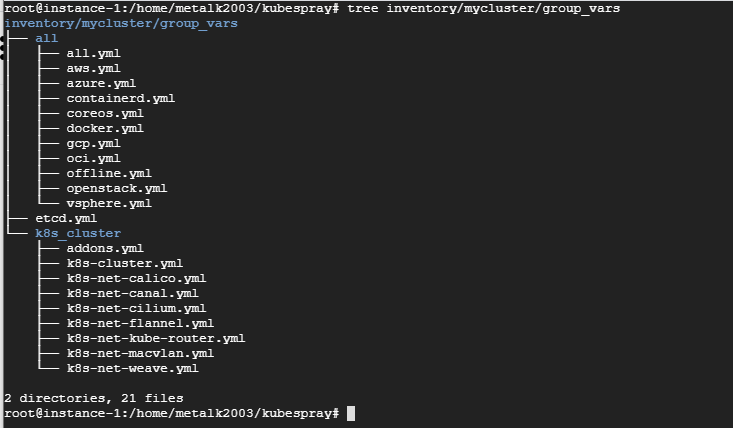
all
● all.yml : Kubespray의 설치 및 설정.
● azure.yml : 애저 환경에 설치할 떄 적용할 설정.
● coreos.yml : 코어 OS 환경에 설치할 때 적용할 설정.
● oci.yml : 오라클 클라우드 환경에 설치할 때 적용할 설정.
● docker.yml : 도커를 설치할 때 적용할 설정.
● openstack.yml : 오픈스택 환경에 설치할 때 적용할 설정.
etcd.yml
> etcd 설치에 필요한 상세 설정 내용.
k8s_cluster
> 쿠버네티스 관련 설정
● k8s-cluster.yml : 쿠버네티스 클러스터를 설치할 때 적용할 설정.
● addons.yml : 쿠버네티스 클러스터를 설치한 후 추가로 설치할 구성 요소 관련 설정.
● k8s-net-*.yml : 쿠버네티스 네트워크 플러그인 별 상세 설정. 네트워크 플러그인은 k8s-cluster.yml 파일의 kube_network_plugin 변수에 설정한 내용을 적용하고, 상세 설정은 본 k8s-net-*.yml 파일의 설정을 따른다.

※ 온프레미스 환경에 쿠버네티스 클러스터를 구성할 때 변경해야 할 점
: 온프레미스 환경에 쿠버네티스 클러스터를 구성할 때는 필수적으로 변경해야 할 설정이 있다.- 대상 파일은 all.yml 과 k8s-cluster.yml 이다.- 첫 번째로 all.yml 파일 안의 http_proxy, https_proxy, no_proxy 필드를 살펴봐야 한다. Kubespray는 클러스터를 구성하는 데 필요한 패키지들과 도커 이미지들을 인터넷에서 다운로드한다. 인터넷에 직접 접근할 수 없는 온프레미스 환경에서는 다음 예처럼 http_proxy, https_proxy 필드에 프록시 설정을 해주어야 한다. no_proxy 필드에는 프록시를 거치지 않을 내부 도메인 등을 명시한다. http_proxy: "http://example.proxy.tld:prot"
https_proxy: "http://example.proxy.tld:prot"
no_proxy: "internal.docker-repo.com, internal.apt-repo.com"
- 두 번째로는 k8s-cluster.yml 파일 안 kube_service_addresses, kube_pods_subnet 필드를 살펴봐야 한다.
- kube_service_addresses 필드에는 쿠버네티스의 서비스 IP(클러스터 IP)로 할당할 대역을 설정.
kube_service_addresses: 10.233.0.0/18
- kube_pods_subnet 필드에는 쿠버네티스 클러스터에 생성되는 파드들이 할당받을 IP 대역을 설정.
kube_pods_subnet: 10.233.64.0/18
- 두 가지 필드의 IP 대역이 온프레미스 환경의 네트워크에서 이미 사용 중인 대역이라면 변경해줘야 한다.
(3-3-2) inventory.ini
: 파일에 설치 대상 서버들의 정보를 설정한다.
$ vi inventory/mycluster/inventory.ini

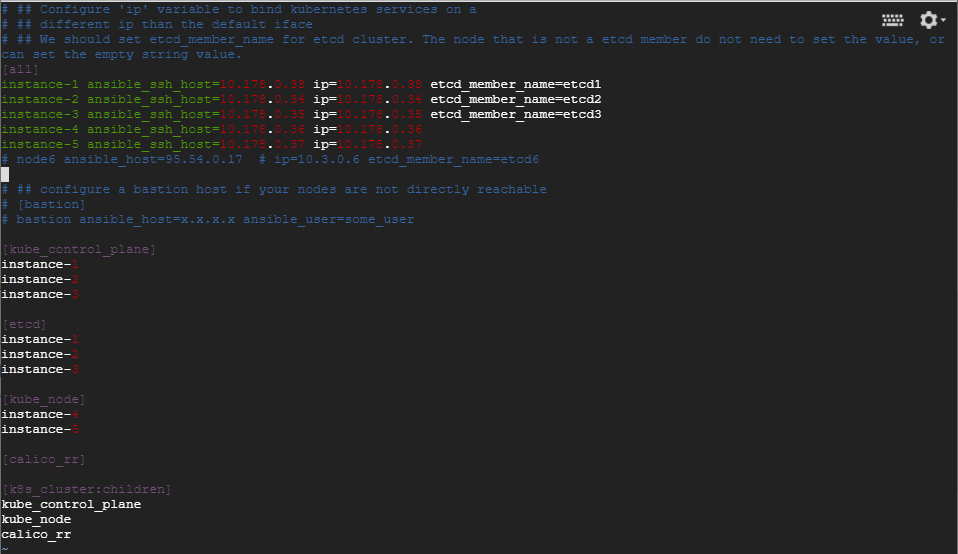
● [all] : 클러스터로 구성될 서버들의 호스트 네임과 IP(이 예에서는 VM 인스턴스의 내부IP)를 설정한다. 참고 로 앤서블에서 해당 서버에 접근할 IP(ansible_ssh_host)와 설정값으로 사용하는 IP(ip)가 같으면 호스트 네임만 입력해 SSH로 통신할 수 있다.
● [kube-master] : 마스터 노드로 사용할 서버의 호스트 네임을 설정한다. 참고로 [all]에서 호스트 네임의 IP 정보 등을 설정했다면 호스트 네임만 입력해도 된다.
● [etcd] : 쿠버네티스의 클러스터 데이터를 저장하는 etcd를 설치할 노드의 호스트네임을 설정한다. etcd와 마스터 노드를 별도로 구성할 수도 있지만 여기에서는 같은 노드로 설정.
● [kube-node] : 워커 노드로 사용할 서버의 호스트네임을 설정한다.
● [k8s-cluster:children] : 쿠버네티스를 설치할 노드들을 설정한다. etcd가 설치될 노드를 제외하는 것이므로 보통 기본 설정 그대로 사용한다.
- 구성할 서버 설정이 끝났다면 쿠버네티스 클러스터를 구성하는 명령을 실행(cluster.yml 스크립트 파일을 실행)
$ ansible-playbook -i inventory/mycluster/inventory.ini -v --become --become-user=root cluster.yml
> 클러스터 구성 대상은 inventory.ini 의 설정을 따른다.
> ansible-playbook 명령어가 Default 저장소(inventory)를 바라보지 않도록 -i 옵션으로 저장소를 지정해서 실행.

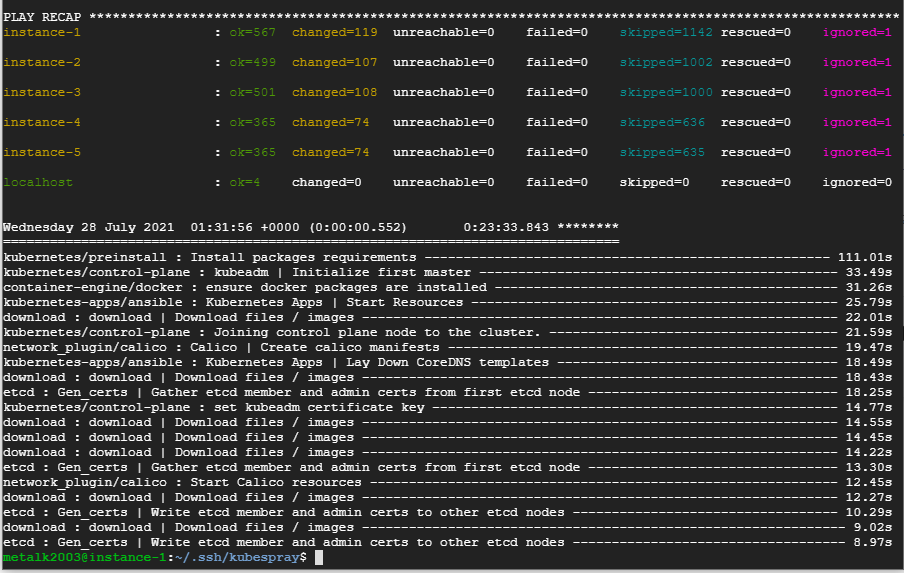

- 클러스터 구성을 완료한 이후에는 마스터 노드에서 root 계정으로 kubectl 관련 명령을 사용할 수 있다.
- sudo -i 명령으로 root 계정으로 변경.
- kubectl get nodes 명령으로 모든 노드가 사용할 수 있는 상태인지 확인.
$ sudo -i
$ kubectl get nodes
- 모든 노드의 STATUS 항목 값이 Ready 라면 클러스터 구성을 완료한 것이다.
- 워커 노드의 기본 역할은 <none>으로 표시.
Reference
- https://book.naver.com/bookdb/book_detail.nhn?bid=16030803