1. uptime
uptime
현재 대기 중인 프로세스가 얼마나 있는 지.
3개의 숫자는 각각 1분, 5분, 15분의 Load Average 값.
리눅스 시스템에서 이 값은 대기 중인 프로세스 뿐만 아니라 Disk I/O와 같은 I/O 작업으로 Block된 프로세스까지 포함된다. 1분 동안 부하율이 급등했다면 오류를 의심해봐야 한다.
2. dmesg
dmesg | tail
dmesg | tail -n 20
시스템 메시지. 가장 많이 그리고 먼저 확인해봐야 하는 것.
- 경로 : /var/log/dmesg
- 부팅 시부터 시작해서 모든 커널 메시지가 출력되기 때문에 tail을 이용해서 보는 것이 좋다.
- dmesg | grep sda : 하드디스크 정보 확인
- dmesg | grep LINUX : 커널 정보 확인
- dmesg | grep eth : NIC 정보 확인
- oom-killer(out of memory):Kill process ...
- TCP: Possilbe SYN flooding on port 7001. Dropping request. Check SNMP counters ...
※ /var/log/messages
cat /var/log/messages | egrep -i "emerg|alert|crit|error|warn|fail"messages 에서 커널과 OS의 표준 프로세스의 로그를 볼 수 있음.
3. vmstat
vmstat
Virtual Memory stat의 약자로 메모리,cpu 등의 정보들을 확인할 수 있다. 메모리 부족 등의 문제를 파악할 때 사용한다.
- r (run queue) : 현재 실행 중인 프로세스의 수
- b (blocked queue) : 인터럽트가 불가능한 sleep 상태에 있는 프로세스의 수 (I/O 처리를 하는 동안 블록 처리된 프로세스).
- swpd : 사용하고 있는 swap 메모리 양. swap 메모리가 사용된다면 메모리 부족 의심해봐야 함.
- free : 사용 가능한 메모리 양 (값은 메모리 최소 단위를 의미하므로 742244 * 4KB = 2968 MB =2.9 GB )
- buff : 버퍼로 사용되고 있는 메모리 양
- cache : 캐시로 사용되고 있는 메모리 양
- si = swap in, so = swap out : 수치가 0보다 높게 발생하면 메모리가 부족한 것으로 볼 수 있다. 단 free 메모리 수치가 높으면 스왑 메모리만 사용하는 것으로 실제 메모리는 여유 있는 것으로 볼 수 있기 때문에 종합적으로 보고 판단해야 함.
- bi : 초당 블록 디바이스로 보내는 블록의 수
- bo : 초당 블록 디바이스로부터 받는 블록의 수
- in : 초당 인터럽트 되는 양
System Call(System)
- sy(system call) : OS의 시스템 영역에서 수행하는 시스템 콜 개수
- cs(context switch) : CPU 내에서 process 간 context 정보를 교체하는 회수
CPU
- us(user CPU) : 사용자 영역에서 사용하는 CPU 비율
- sy(system CPU) : 시스템 콜에 호출에 의해 사용되는 CPU 비율
- id(idle CPU) : 사용 가능한 CPU 비율 (일반적으로 100-(us+sy)=id)
- wa(wait I/O) : disk 혹은 기타 I/O 작업으로 인해 대기하는 CPU
CPU 점유율이 높다고 고객이 언급할 경우 필수적으로 해당 CPU가 us인지 sy인지 확인해야 한다. 어느 CPU가 높으냐에 따라서 원인 분석을 위한 명령어가 달라진다.
us가 높을 경우 일반적으로 OS 명령어를 통해 바로 알 수 있는 경우는 많지 않으며, java인 경우 kill -3 과 ti 명령을 통해 대략적으로 확인할 가능성이 높다.
sy가 높을 경우는 java/c 할 거 없이 truss 명령을 통해 어떠한 시스템 콜이 수행 중인지 확인한다.
4. mpstat
mpstat
mpstat 1
mpstat -P ALL 1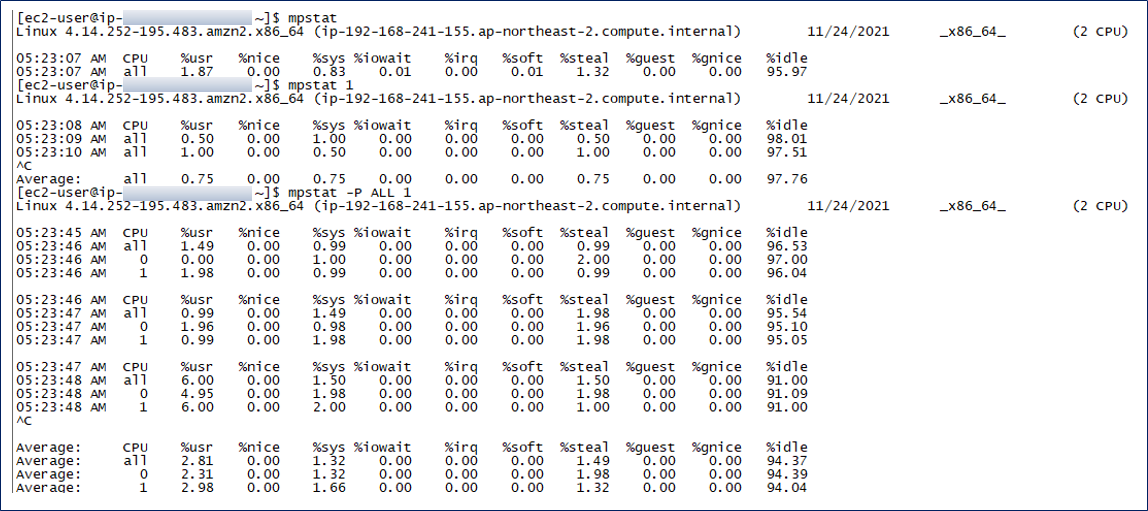
CPU Time을 CPU 별로 측정할 수 있다. 이 방법을 통하면 각 CPU 별로 불균형한 상태를 확인할 수 있다. 만일, 한 CPU만 일하고 있는 것은 Application이 single thread로 동작한다는 의미이다.
- mpstat -P ALL 1 옵션을 주면 각 CPU 별로 1초마다 상세히 확인할 수 있다.
5. pidstat
pidstat
pidstat 1
Process 당 top 명령어를 수행하는 것과 비슷하다. Process 당 cpu 사용률도 확인이 가능하다.
6. iostat
iostat
iostat -xz
iostat -xz 1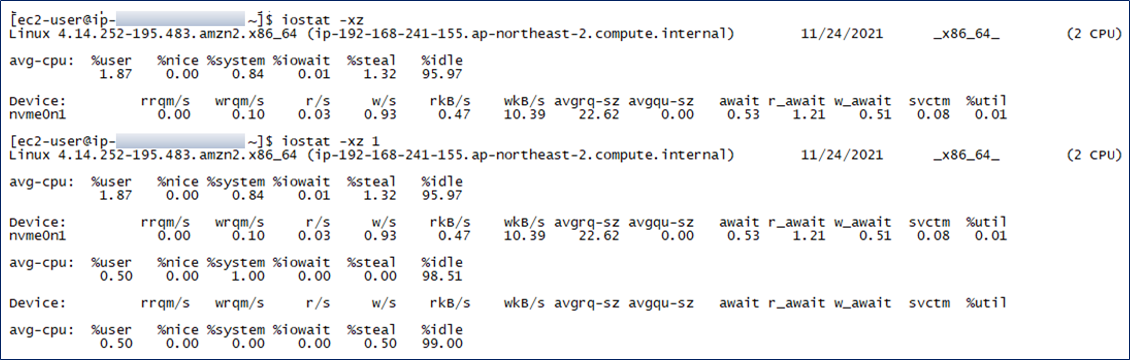
디스크 모니터링.
- iostat -xz 1 옵션을 주면 1초 마다의 상세한 모니터링을 할 수 있다.
7. free -m
free -m
메모리 상태.
- 실질 메모리 Usage = (used-buffers-cached)/total
- free만 볼 것이 아니라 buffer와 cache 사용량 전체적으로 확인해야 한다.
- buffers : Block I/O의 buffer 캐시. 사용량
- Cached : 파일 시스템에서 사용되는 page cache의 양.
- 위 값들이 0에 가까워지면 안 된다. 이는 곧 높은 Disk I/O가 발생하고 있음을 의미한다.(iostat으로 확인)
- 리눅스는 빠르게 다시 애플리케이션에 메모리가 할당될 수 있도록 캐시 메모리를 사용한다. 따라서 캐시 메모리도 여유 메모리에 포함되어 보여야 한다.
8. sar -n DEV
지금 현재의 시스템 상황보다는 이전의 로그를 바탕으로 어떤 시기에 어떤 일들이 있었는가를 측정하여 시스템의 장기적인 부하량을 예측하고 대처할 수 있도록 해주는 명령어
sar -n DEV 1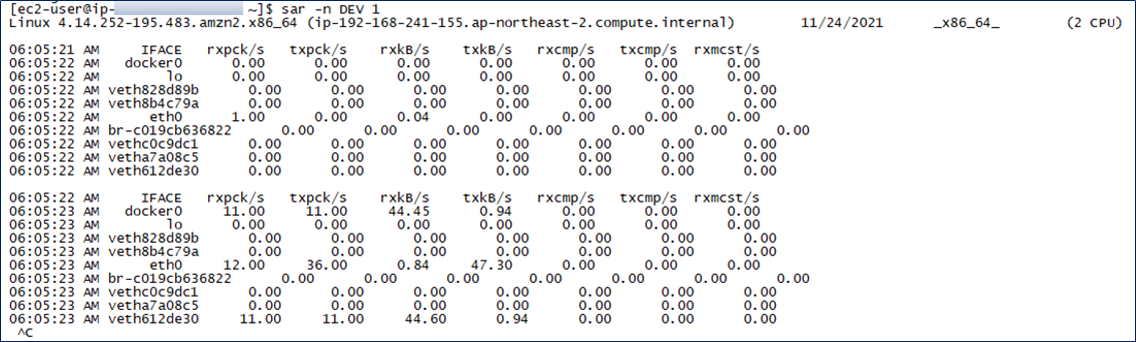
네트워크 처리량 확인
9. sar -n TCP,ETCP
sar -n TCP,ETCP 1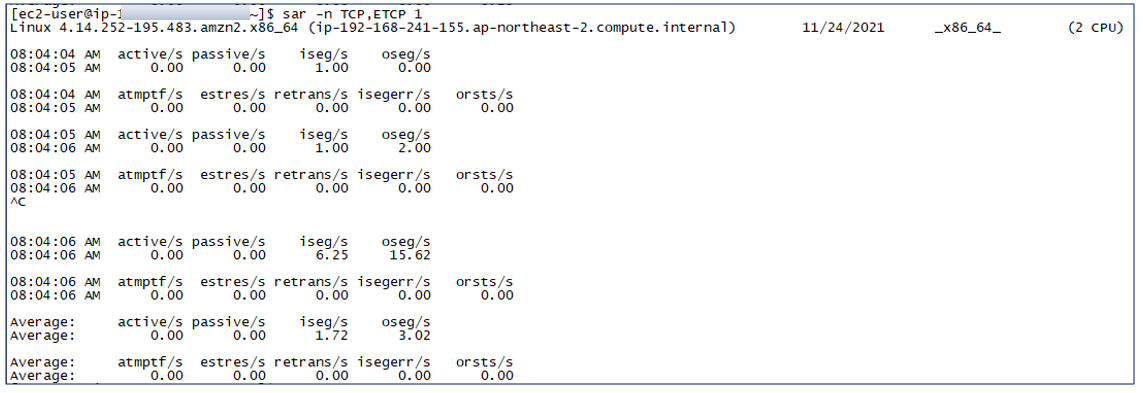
TCP 통신량 확인
- active/s : 로컬에서부터 요청한 초당 TCP 커넥션 수 (예를 들어, connect()를 통한 연결)
- passive/s : 원격으로부터 요청된 초당 TCP 커넥션 수 (예를들어, accept()를 통한 연결)
- retrans/s : 초당 TCP 재연결 수
active와 passive 수를 보는 것은 서버의 부하를 대략적으로 측정하는 데에 편리하다. retransmits은 네트워크나 서버의 이슈가 있음을 이야기한다. 신뢰성이 떨어지는 네트워크 환경이나(공용 인터넷), 서버가 처리할 수 있는 용량 이상의 커넥션이 붙어서 패킷이 드랍되는 것을 의심할 수 있다.
10. top
top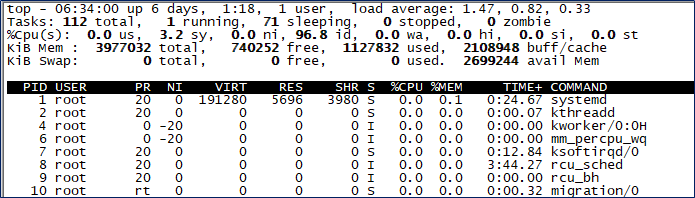
전반적인 시스템 확인 명령어
S(Process Status)
- D : 인터럽트 불가
- R : 실행 중
- S : 잠(Sleep)
- T : 정지 중
- Z : 좀비 프로세스
11. ps -aux
ps -aux
ps -aux --sort=-%cpu
ps auxf
- ps -aux --sort=-%cpu // CPU 점유율 높은 순서로 내림차순으로 정렬시켜 점유율 높은 프로세스 확인
- ps auxf // 프로세스의 친자관계를 볼 수 있다 ( =pstree )
'OS > Linux Server' 카테고리의 다른 글
| [Linux] Root 비밀번호 분실 시 찾기 (0) | 2021.12.13 |
|---|---|
| [Linux] Linux에서 Docker를 운영하는 이유 (0) | 2021.11.29 |
| [Linux] File System (0) | 2021.11.23 |
| [Linux] Linux Directory 구조 (0) | 2021.11.23 |
| Linux 실질 메모리 사용률 계산 (0) | 2021.11.04 |



